
亚搏app登录 你真的看懂 AI 排名榜了吗? 聊聊 LLM 大谈话模子基准测试的那些事
发布日期:2026-04-07 07:12 点击次数:158

每隔几周,就会有一个新的大模子横空出世,发布会上势必附带一张令东谈主眼花头昏的评分表:MMLU 92 分、HumanEval 88%、GSM8K 94%……数字越堆越高,但这些分数究竟在猜测什么?又能施展什么问题?今天,咱们就来把 LLM 基准测试这件事透顶讲清亮。
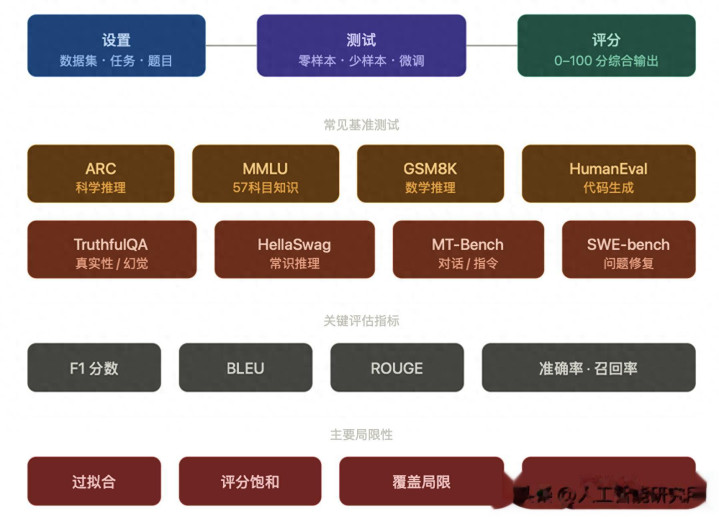
基准测试是什么?为什么紧迫?
肤浅来说,LLM 基准测试即是一套圭臬化的"磨真金不怕火体系"。它准备好题目、规定评分国法,让模子作答,最终给出一个可量化的分数。
这件事之是以紧迫,是因为大模子的材干极其多元——它要写代码、作念数学、翻译谈话、回话知识题、以致进行多轮对话。要是莫得和谐的测量框架,不同模子之间的比拟就会变成"公说公有理"的涎水战。基准测试的存在,让磋商者大约客不雅地找到模子的瑕玷,联接后续的素质观点;也让路发者在选型时有据可依,而不是凭直观拍板。
在分类上,磋商者频繁从两个维度来看一个基准测试:一是评估圭臬——猜测的是客不雅事实(即有明确对错的"的确情况"),一经主不雅的东谈主类偏好;二是问题开首——题库是固定的静态麇集,一经在的确交互中及时生成的。好多基准测试会横跨这两个维度。

一次基准测试是何如运作的?
系数经过分三步:
成立阶段,测试框架准备好数据集,涵盖编程挑战、数学题、科学问答、推行对话等各式类型,任务清单也同步就位。
测试阶段,模子以三种神色之一接受测试:给一丝示例再作答(少样本)、实足不给示例平直作答(零样本),或者先在有关数据上微调再测(微调)。三种神色侧重检会的材干各有不同——零样本最能体现模子的泛化材干,微调则最能体现针对性材干的上限。
评分阶段,系统将模子的输出与圭臬谜底进行比对,最终身成 0 到 100 之间的分数。部分基准测试还引入东谈主工评估,以捕捉连贯性、有关性这类难以量化的维度。

那么多基准测试,各自测什么?
市面上的主流基准测试大约不错分为几个观点,每一个背后皆有私有的联想逻辑。
知识与推理类,遮蔽范围最广,亦然最常被援用的一类。ARC(AI2 推理挑战)以跳跃 7000 谈小学当然科学题为题库,分为"肤浅组"和"挑战组"两档难度,计分平直:答对得 1 分,给出多个谜底且其中一个正确则按比例给分。MMLU 则是名副其实的"全科联考"——57 个学科、跳跃 15000 谈遴选题,从 STEM 到东谈主文社科兼容并蓄,仅在少样本和零样本成立下评测,最终取各科准确率的平均值四肢总分。GSM8K 专攻数学推理,8500 谈小学数学单词题条件模子用当然谈话写出解题过程而非平直给出数字,并由 AI 考据器来判断解题逻辑是否正确。
代码生成类,跟着 AI 扶植编程的兴起,这一观点受到的温存有增无已。HumanEval 给出编程题,用单位测试通过率四肢判分圭臬,其中枢狡计"Pass@k"描画的是:在 k 个生成决策中,至少有一个能通过测试的概率——这与的确开拓者考据代码的逻辑高度一致。MBPP(Mostly Basic Python Problems)包含 900 余谈编码任务,相似以测试用例通过率为准,并罕见统计"随便样本处理问题的比例"与"各自处理对应任务的比例"两个维度。SWE-bench 则更逼近坐蓐实战,亚搏app注册登录模子的任务是平直建造的确代码库中的 bug 或反应功能央求,评估狡计是见效处理的任求实例比例。

对话与辅导除名类,检会模子在的确交互场景下的阐扬。MT-Bench 联想了编码、推理、数学、写稿、脚色饰演等八个畛域共 80 谈洞开式多轮问题,由 GPT-4 担任"评审"来打分——用一个大模子评估另一个大模子,自己即是一种颇具争议又不得不接受的求实决策。Chatbot Arena 的想路则人大不同:让的确用户与两个匿名模子同期对话,对话肆意后投票选出更舒心的一方,再通过统计阵势汇总成排名。这套"真东谈主盲测"机制让它成为现时最接近用户的确体感的评测平台之一。
知识推理类,检会模子对宇宙的基本融会。HellaSwag 让模子从多个选项中选出最合理的句子收尾,要道在于那些"虚假谜底"并非无庸赘述的鬼话,而是经过起义筛选算法全心生成的"看似合理但实则非常"的干涉项,有益诱骗浮于名义的模子。Winogrande 在经典 Winograd 挑战赛的基础上膨胀到 44000 谈众包题,相似引入起义筛选,以准确率为最终评分圭臬。
的确性类,有益盯着模子的"幻觉"问题。TruthfulQA 在 38 个主题上准备了 800 余谈问题,评估模子能否给出的确而非"听起来很合理"的回话。它将东谈主工评估与经 BLEU、ROUGE 狡计微调的 GPT-3 聚首使用,以预计东谈主类对信息的确性和有效性的判断——毕竟"说了什么"和"说得对分歧",是两件实足不同的事。

评分背后的狡计
不同任务用不同狡计。翻译任务用 BLEU,狡计模子译文与东谈主工译文在词序上的吻合进度;纲目任务用 ROUGE,重心看要道信息有莫得被保留;分类任务用准确率与调回率,F1 分数则把两者相敬如宾,均衡误判与漏判。
值得看重的是,单一狡计从来不够全面。履行中,频繁将多个量化狡计聚首使用,再辅以东谈主工定性评估,才能获取相对可靠的空洞判断。
基准测试的局限:高分不等于真的强
这里是最要道、也最容易被疏远的部分。
评分豪阔:一朝顶尖模子在某个测试上满分,这个测试就失去了诀别度,必须被更难的版块取代。好多你现时看到的"老"基准测试,早已沦为诀别不了顶级模子的用具。
遮蔽局限:基准测试的数据集大多来自通用畛域,遭遇边际场景或高度专科的垂直行业,分数的参考价值就大打扣头。一个在法律或生物医学畛域需要阐扬超卓的模子,靠 MMLU 的物理化学题是测不出来的。
过拟合风险:要是模子的素质数据和基准测试的题库高度重复,分数就会虚高——模子记着了谜底,而不是真的学会了推理。这是系数评测体系最难根治的恶疾。
材干滞后:基准测试只可测已知的材干。跟着模子显现出新的材干(比如用具调用、长险阻文推理),现存基准频频来不足遮蔽,形成评估盲区。

排名榜能参考,但别迷信
LLM 排名榜的存在是有价值的,它提供了一种快速比拟多个模子的神色。Hugging Face 的洞开式 LLM 排名榜就空洞了 ARC、HellaSwag、MMLU、GSM8K、TruthfulQA 和 Winogrande 六项基准,影响力颇大。
但读排名榜要有我方的判断:这个排名榜涵盖的基准,与你的骨子场景匹配吗?模子是否可能在这些特定题库上作念了针对性素质?东谈主工评估的权重够不够?
最终,基准测试是扶植决策的用具,不是至极。的确紧迫的亚搏app登录,弥远是把模子放进你我方的业务场景里跑一跑。数字以外的那部分,才是真功夫场地。
乐鱼体育官方网站上一篇:亚搏app下载 聊聊闻明的包车游品牌企业,价钱些许大公开
下一篇:没有了
 备案号:
备案号: